Adler, R. J. (1981). The Geometry of Random Fields. Wiley, Chichester, UK. Reprinted by SIAM, 2010.
Benjamini, Y. and Hochberg, Y. (1995). Controlling the false discovery rate: A practical and powerful approach to multiple testing. Journal of the Royal Statistical Society, Series B, 57, 289-300.
Benjamini, Y. and Heller, R. (2007). False discovery rates for spatial signals. Journal of the American Statistical Association, 102, 1272-1281.
Benjamini, Y. and Yekutieli, D. (2001). The control of the false discovery rate in multiple testing under dependency. Annals of Statistics, 29, 1165-1188.
Bolin, D. and Lindgren, F. (2015). Excursion and contour uncertainty regions for latent Gaussian models. Journal of the Royal Statistical Society, Series B, 77, 85-106.
Brown, D. A., Lazar, N. A., Datta, G. S., Jang, W., and McDowell, J. E. (2014). Incorporating spatial dependence into Bayesian multiple testing of statistical parametric maps in functional neuroimaging. NeuroImage, 84, 97-112.
Chevallier, F., Fisher, M., Peylin, P., Serrar, S., Bousquet, P., Bréon, F.-M., Chédin, A., and Ciais,P. (2005). Inferring CO$_2$ sources and sinks from satellite observations: Method and application to TOVS data. Journal of Geophysical Research, 110, D24309, doi:10.1029/2005JD006390.
Chevallier, F., Bréon, F.-M., and Rayner, P. J. (2007). Contribution of the Orbiting Carbon Observatory to the estimation of CO$_2$ sources and sinks: Theoretical study in a variational data assimilation framework. Journal of Geophysical Research, 112, D09307, doi:10.1029/2006JD007375.
Chevallier, F., Feng, L., Bösch, H., Palmer, P. I., and Rayner, P. J. (2010). On the impact of transport model errors for the estimation of CO$_2$ surface fluxes from GOSAT observations. Geophysical Research Letters, 37, L21803, doi:10.1029/2010GL044652.
Chevallier, F., Palmer, P. I., Feng, L., Boesch, H., O'Dell, C. W., and Bousquet, P. (2014). Toward robust and consistent regional CO$_2$ flux estimates from in situ and spaceborne measurements of atmospheric CO$_2$. Geophysical Research Letters, 41, 1065-1070, doi:10.1002/2013GL058772.
Cooley, D., Nychka, D., and Naveau, P. (2007). Bayesian spatial modeling of extreme precipitation return levels, Journal of the American Statistical Association, 102, 824-840.
Craiu, R. V. and Sun, L. (2008). Choosing the lesser evil: trade-off between false discovery rate and non-discovery rate. Statistica Sinica, 18, 861-879.
Cressie, N. (1993). Statistics for Spatial Data (revised edition). Wiley, New York, NY.
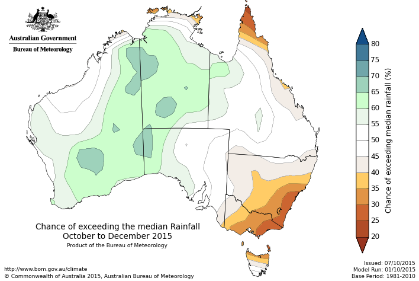
Cressie, N. and Suesse, T. (2020). Great expectations and even greater exceedances from spatially referenced data.
Davison, A. C., Padoan, S. A., and Ribatet, M. (2012). Statistical modeling of spatial extremes. Statistical Science, 27, 161-186.
Dunn, O. J. (1961). Multiple comparisons among means. Journal of the American Statistical Association, 56, 52-64.
French, J. P. and Sain, S. R. (2013). Spatio-temporal exceedance locations and confidence regions. Annals of Applied Statistics, 7, 1421-1449.
Gumbel, E.J. (1958). Statistics of Extremes. Columbia University Press, New York, NY. Reprinted by Dover Press, 2004.
IPCC (2013). Climate Change 2013: The Physical Science Basis. Contribution of Working Group I to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change. Stocker, T. F., Qin, D., Plattner, G.-K., Tignor, M., Allen, S. K., Boschung, J., Nauels, A., Xia, Y., Bex, V. and Midgley, P. M. (eds.). Cambridge University Press, Cambridge, United Kingdom and New York, NY, USA, 1535 pp. Obtained from http://www.ipcc.ch.
Kharin, V. and Zwiers, F. (2005). Estimating extremes in transient climate change simulations. Journal of Climate, 18, 1156-1173.
Reich, B. J., Fuentes, M., and Dunson, D. B. (2011). Bayesian spatial quantile regression. Journal of the American Statistical Association, 106, 6-20.
Schlather, M. and Tawn, J. (2003). A dependence measure for multivariate and spatial extremes: Properties and inference. Biometrika, 90, 139-156
Storey, J. D. (2003). The positive false discovery rate: A Bayesian interpretation and the q-value. Annals of Statistics, 31, 2013-2035.
Storey, J. D. and Tibshirani, R. (2003). Statistical significance for genome-wide studies. Proceedings of the National Academy of Sciences of the United States of America, 100, 9440-9445.
Sun, W., Reich, B. J., Cai, T. T., Guindani, M., and Schwartzman, A. (2015). False discovery control in large-scale spatial multiple testing. Journal of the Royal Statistical Society, Series B, 77, 59-83.